索引順編成ファイルについてもう少し詳しく
- 1.どんなファイルか
-
最初に注意しておきますが、NECのオフコンの索引順編成ファイルは、通常世間一般に索引編成、索引順編成と言われているファイル形式とはかなり異なります。(あふれ域というようなものもありません。)普通の索引順編成ファイルの簡易版といった感じです。
あるキーで検索してそのキーに対応するデータを読み込んだり、書き換えたりできるファイルです。キーは1種類だけでレコード中に連続した領域になければなりません。
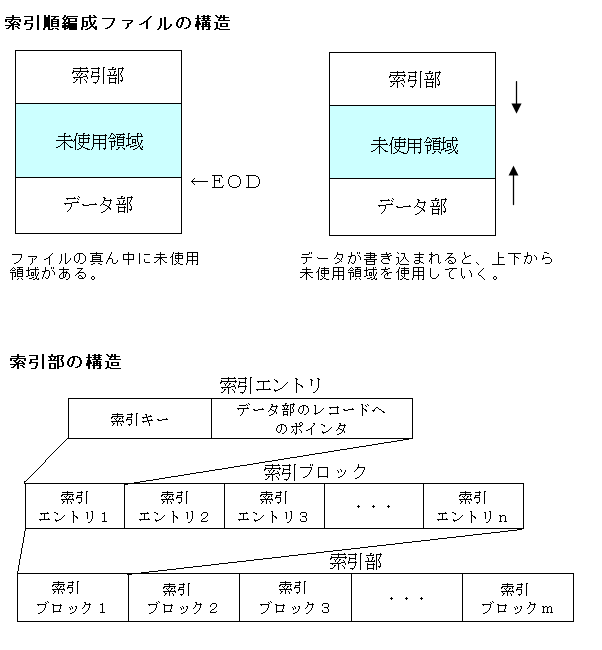
1つのファイル中に索引部と呼ばれる部分とデータ部と呼ばれる部分がある構造のファイルになります。実際のデータ(例えば顧客の名前や売り上げ金額とか)はデータ部に入っています。
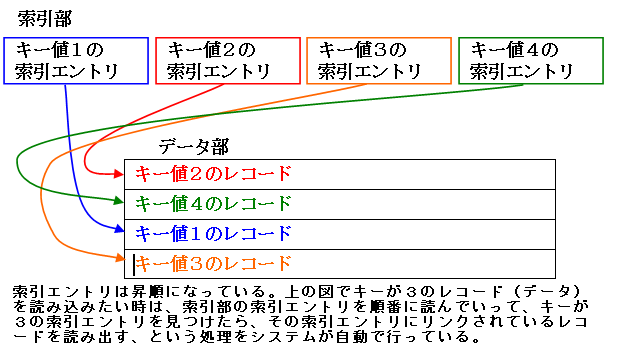
索引部には、索引キーと実際のデータが入っているレコードへのポインタの組(索引エントリという)がレコード数分入っています。索引エントリはキーの昇順に並んでいます。
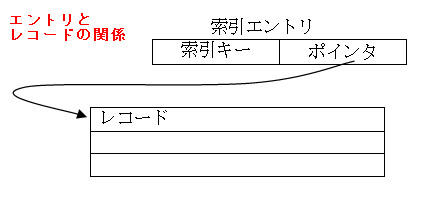
全ての索引エントリはポインタを介して対応するレコードにリンクされています。
あるキーで読み込みを行うと、たくさんある索引エントリの中からその索引キーの入ったエントリを探し出し、ポインタでリンクされているレコードの情報を読み込むという動作をします。
<データ部>
データ部は、EODがあります。他のファイルとの違いとして、順編成や相対編成ファイルはデータを書き込むとアドレスの低位番地から高位番地にEODが移動するのに対して、索引順編成ファイルは高位番地から低位番地にEODが移動する点です。
データを削除すると、順編成ファイルや相対編成ファイルと同様に削除レコードが発生します。順編成や相対編成ファイルと異なるのは、ファイル再編成をしなくても削除レコードは自動的に再利用されるということです。(削除レコードチェインで管理してうまく再利用している。)
<索引部>
索引エントリは複数集まって索引ブロックを構成しています。索引部は複数の索引ブロックの集合になっています。
索引エントリは昇順に格納されており、レコードの削除、追加があるとその度に昇順になるように再編成が行われます。
- 2.索引ブロックの仕組み
-
索引順編成ファイルを作る時に、使用効率というパラメータがあります。
これが何かを説明するためには、索引ブロックの仕組みを説明する必要があります。
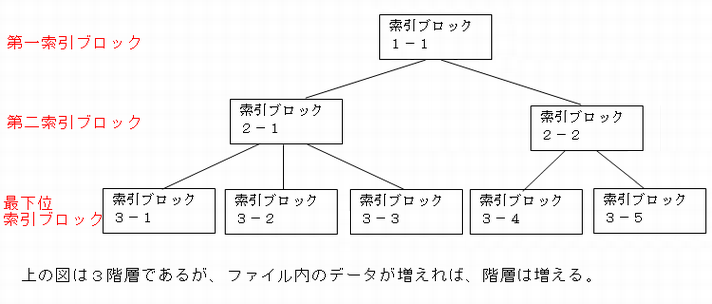
基本的に索引部はB+ツリー構造になっています。
索引ブロックは第一レベルの索引ブロック、第二レベル以降の索引ブロック、最下位レベルの索引ブロックに別れています。
最下位レベルの索引ブロックに索引エントリが入っています。それ以外の索引ブロックには1つ下位の索引ブロックへのポインタが入っています。
レコード(データ)をどんどん追加していくと、索引エントリが増えていき、そのうちに索引ブロックに入りきらなくなります。そうなると新しい索引ブロックを1個作り、オーバーフローした索引ブロック中の索引エントリを2つの索引ブロックに分けます。
具体的に例で説明します。
9個の索引エントリの入る索引ブロックがあるとします。最初は全ての索引エントリは未使用状態とします。

今データを入力したため、レコードを登録し、そのキーを索引部に登録することになりました。
索引エントリにキーAが登録されました。

次々にデータ入力がされ、索引エントリにキーが登録されていきます。

索引ブロックが満杯になってしまいました。この状態でさらにキーを登録しようとすると、キー分割が行われます。

新しく索引ブロックが作られ、索引エントリが2つの索引ブロックに振り分けられます。
この振り分け方を指定するのが、使用効率というパラメータです。
使用効率が50%のとき、2つの検索ブロックに半分ずつ振り分けられます。

使用効率100%で指定した場合は、下の図のように元の索引ブロックは100%使用された状態、新しい索引ブロックに新しく登録したキーが登録された状態となります。

- 3.キー
-
索引順編成ファイルで登録できるキーの数は1個だけです。キーは連続した領域になければなりません。
索引順編成ファイルを作る時に、既に登録済みのレコードと同一のキー値を持つレコードをさらに追加できるかどうかを指定できます。同一のキー値を許す場合「二重キーあり」でファイルを作ります。同一のキー値を許さない場合は「二重キーなし」でファイルを作ります。
ファイルを作った後に「あり」を「なし」にしたり、逆に「なし」から「あり」に変更することはできません。
二重キーありにすると二重キーを管理するための「補足レコード」というものが作られ、そのレコードへのポインタ用にデータレコードの長さが8バイト増えます。
- 4.索引順編成ファイルの作成
-
ファイルの作成をする時には、作るファイルの大きさに気をつける必要があります。1つのファイル中に索引部とデータ部が入るので、順編成ファイルのようにデータ分のサイズを用意すればいいのではなく、索引部も含めたサイズでファイルを作らなければなりません。
索引順編成ファイルはファイル作成後にエクステントの拡張や追加はできないので、後からファイルサイズを動的に増やすということはできません。最初にファイルを作る時のファイルサイズが重要になります。ファイルがオーバーフローしたら、別の大きなファイルをもう1個作り、そこに全データをコピーしていくことになります。
索引順編成ファイルはマルチエクステント構成を取ることができないので、作ることのできる最大のファイルサイズは1エクステント分即ち1,048,575セクタまでとあまり大きなファイルはつくれません。
- 5.オーバーフロー
-
これはかなり運が悪い時にだけに起きるらしいのですが、索引順編成ファイルの特性上、まれに一旦ファイルオーバーフロー状態になるといくらレコードを削除してもなかなかオーバーフロー状態を解除できなくなってしまうことがあるそうです。大量のレコードを削除する(削除キーブロックができるとオーバーフロー状態を解除できる)か、オーバーフローになったファイルは捨ててもっと大きなファイルを作り直すことでオーバーフローを解除します。これは仕様らしいので、このようになったら諦めてがんばって復旧するしか方法はないようです。(オーバーフローになる直前のレコード追加でキー分割が発生し、中途半端に未使用セクタが残ると起きるらしい。これはダメじゃないのかという気がしますが・・・。)
索引順編成ファイルはエクステントの拡張/追加もできず、削除レコードも自動的に再使用される仕組みであるので、順編成ファイルや相対編成ファイルのようなオーバーフロー回避手段は取ることができないため、オーバーフローになった場合は、さらに大きなファイルに作り直すしか手がありません。
- 6.チューニング
-
どのくらい効果があるかは、そのシステムの状態によりますが、索引順編成ファイルのアクセスを高速化できるかもしれない方法がいくつかあります。
初級の域を越えているので、簡単に紹介するだけにとどめます。
- データブロック長の変更(これはA−VXのシステムの特性上、ブロック長を 1〜512,769〜1024,1793〜2048,3841〜4096の範囲にすると効率良くファイルアクセスできるため、アクセスを高速化できることがある。)
- 1索引ブロック内の索引エントリの数を増やす。使用効率の値を上げる。
- もしソートされたデータを一括入力するならば、キーの昇順にソートするよりも逆順にソートしたデータを一括入力したほうが若干処理が速くなる可能性が高い。索引順編成ファイルの構造上、同じデータならば昇順より逆順の方がファイルI/O回数が減る可能性が高いため。(今はディスクのアクセス速度が昔より高速なので、おそらくどっちでもほとんど変わらないはず。)
- 7.索引順編成ファイルを使用する場合
-
索引順編成ファイルは、削除レコードが自動的に再利用されるという利点はありますが、あまり大きなファイルが作れない、エクステントの拡張/追加ができない、未クローズ発生時の復旧が面倒、強制読み出し機能が使えない、削除レコードが読み出せない、と欠点がたくさんあります。複数索引順編成ファイルがあるので、索引順編成ファイルはなるべく使用しないのがよろしいかと思います。
索引順編成ファイルは、複数索引順ファイルを利用するまでもないような比較的小サイズのデータで乱アクセスは行うが、使用中のデータの追加や削除が少ない、といった用途に使用するとよいでしょう。


