A−VXのファイル(後半)
- 4.ファイル編成の種類
Windowsのファイルは、テキストファイルやバイナリファイルのようにいろいろな種類があります。A−VXも同じようにいくつかの種類のファイルがあります。A−VXのファイル編成は、全部で以下の種類があります。
- 順編成ファイル
- 相対編成ファイル
- 索引順編成ファイル
- 複数索引順編成ファイル
- 待機区分編成ファイル
- 待機結合編成ファイル
- データベースファイル
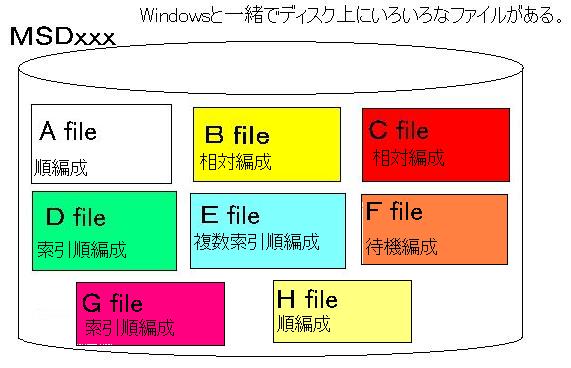
注意点としては、A−VXと世間で一般的に言われている○○編成ファイルでは、同じ名前でも構造が異なっているものがあります。たとえば索引(順)編成ファイルは、かなり簡単な構造になっています。(だからここの説明はメインフレームのファイル構造の勉強にはあまり役に立たないかもしれませんよ。)
- 4.1 順編成ファイル
Windowsのテキストファイルのような形式のファイルです。テキストファイルは1行に何文字(何バイト)も書けますが、A−VXの順編成ファイルは1行に書ける文字数(バイト数)が決まっています。(1行=1レコード)
ファイルを読み込んだり、書き込んだりする時は、先頭のレコードから順番に行います。つまり、順編成ファイルは順アクセスしかできず、乱アクセスや動的アクセスはできないということです。
順編成ファイルについては、別にもう少し詳しく説明します。
- 4.2 相対編成ファイル
-
順編成ファイルに、相対レコード番号というキーが追加されたような感じのファイルです。
1レコードが固定長であったり、ブロック化できるという部分は順編成ファイルと全く同じです。
順編成ファイルのようにファイルの順番に読み込んだり書き込んだりもできるし、相対レコード番号を利用して、ファイルの途中のレコードから読み書きすることもできます。つまり、相対編成ファイルは、順アクセス、乱アクセス、動的アクセス可能ということです。
相対編成ファイルについては、別にもう少し詳しく説明します。
- 4.3 索引順編成ファイル
-
索引部とデータ部で構成されているファイルです。データ部中に1つだけ索引キーがあり、そのキーを使ってファイルの途中のレコードから読み書きすることができます。もちろんファイルの先頭から読み書きすることも可能です。索引順編成ファイルは、順アクセス、乱アクセス、動的アクセス可能ということです。
索引順編成ファイルについて、別にもう少し詳しく説明します。
- 4.4 複数索引順編成ファイル
-
索引順編成ファイルのデータ部の索引キーと索引部が複数ある編成ファイルです。磁気ディスク上に作成できます。キーが複数あるため、データの追加・削除を行った場合、キーの再編成を行う必要があります。あとはだいたい索引順編成ファイルと同じ。
複雑な構造のファイルのため、いろいろと注意事項があります。「データ管理説明書」の「複数索引順編成ファイル」の「プログラミング上の注意事項」を読みましょう。
複数索引順編成ファイルについて、別にもう少し詳しく説明します。
- 4.5 待機区分編成ファイル
これは、一般的にはCOBOLプログラム上やユーザプログラムから読んだり書いたりできない、A−VXのシステム専用のファイルです。LMライブラリファイル(LML)などのようなライブラリファイルが待機区分編成ファイルです。
使用目的が限られており、データファイルとして使用できません。
待機区分編成ファイルについて、別にもう少し詳しく説明します。
- 4.6 待機結合編成ファイル
これも、一般的にはCOBOLプログラム上やユーザプログラムから読んだり書いたりできない、A−VXのシステム専用のファイルです。SUライブラリファイル(SUL)やCUライブラリファイル(CUL)、ジョブストリームファイル(JS)などのライブラリファイルが待機結合編成ファイルです。
使用目的が限られており、データファイルとして使用できません。
待機結合編成ファイルについて、別にもう少し詳しく説明します。
- 4.7 データベースファイル
-
A−VXでは、データベースファイルの実態は複数索引順編成ファイルです。
- 5.ファイル名
以上のファイルは、いくつでも作れます。Windowsと同じようにファイル名を付けて区別します。
ファイルには、システムが使用目的をある程度決めているファイル(システムファイル)とユーザが自分で作るファイル(ユーザファイル)の2種類があります。
システムファイルは、「SYS@」という文字で始まるファイル名となっています。ユーザファイルには「SYS@」で始まるファイル名は付けてはいけません。ユーザファイルのファイル名は最大17文字です。
- 6.システムファイル
ユーザファイルは、必要に応じて自由に作成したり削除したりできます。システムファイルも、作成したり、削除したりできることもできますが、勝手にそういうことをするとおそらくサーバが動かなくなったり、変な動きをしたりするようになると思います。
システムファイルは、「この名前のファイルは××という用途に使う」というようにそれぞれ用途が決まっています。
システムファイルの例
- SYS@LML
- SYS@CAT
- SYS@WK
- SYS@JSL
どのA−VXのシステムでも、SYS@LMLはシステムのロードモジュールを入れるためのファイルであり、SYS@CATはシステムのカタログ情報を入れるファイルです。「うちのシステムではSYS@CATはロードモジュールを入れるために使うよ」なんてことはできません。
逆にどんな名前のシステムファイルがどんな用途に使われているか知っていれば、初めて見るシステムでも必要なファイルや情報を取り出すことができるかもしれません。少なくともシステム分析の取っ掛かりを掴むことはできます。
システムファイルという特別なファイル編成があるというわけではありません。それぞれのシステムファイルは、上で説明した7種類のファイル編成のうちのどれかになります。例えばSYS@LMLは待機区分編成ファイル、SYS@WKは順編成ファイル、SYS@JSLは待機結合編成ファイルとなります。
- 7.常駐ファイルと一時ファイル
ファイルの分け方として、常駐(レジデント)ファイルと一時(テンポラリ)ファイルという区分けがあります。
テンポラリファイルとは、作業用に一時的に使用するファイルで、プログラムを実行したときに作られ、終了時に消えるようなファイルです。レジデントファイルは、プログラムが実行している、いないにかかわらず、常にハードディスクなどにあるファイルです。
- 8.ファイルの確保
ファイルにデータを書き込む前に、ファイルの領域確保が必要です。ここがWindowsのファイルの使い方とは違います。A−VXのファイルは、まずどのような編成のファイルをどの磁気ディスク上に何という名前で何セクタ分作るのかという情報の設定を行う必要があります。つまりあらかじめ「ハードディスクにxxバイト分、Aという名前のファイル用に場所を予約します」と宣言することです。それから、そのファイルに対して書き込んだり読み込んだりできるようになります。
Windowsとかは、ファイルを書き込む前にハードディスクにファイル格納用の場所を予約する作業は必要はないですよね。例えばワードで文書を作成する前に、「今から書く文書はファイルにすると1000バイト分だから、ハードディスク上に1000バイト分書き込めるようにあらかじめ予約しておかなくっちゃね。」なんて作業はないと思います。なんとなくワードで文書を書いて、ファイルの保存するボタンをクリックすれば適当にハードディスクに文書ファイルができてしまう。
A−VXは、初めてファイルに書き込む場合は、書き込む前に「えーと、これから書くファイルは、最大で1000バイトになるから、ハードディスク上に1000バイト分の場所を予約しなきゃ。」と言って、予約する作業が必要になります。これが領域確保です。
最初に一度領域確保(予約)しておけば、そのサイズの範囲内で自由に読み書きできます。
あえて言うなら、ワードで最初に文書を保存するときは「名前を付けて保存」でファイル名を決めたりしますが、2回目以降は「上書き保存」で自由に書きこめます。ワードの「名前を付けて保存」がA−VXのファイルの領域確保、後は「上書き保存」でどんどん書き込めるように、A−VXも領域確保(予約)した範囲でどんどん書き込める、というところが似ているといえば似ているでしょうか。
領域確保するとそのサイズの範囲内で自由に読み書きできると書きました。例えば1000バイト分領域確保(予約)していて、どんどん書き込んでいって1000バイトを超えたらどうなるでしょうか。もう書き込めないので、ファイルオーバーフローというエラーになります。
ファイルオーバーフローになったら、もう書き込めないので、領域確保(予約)するサイズを大きくしなければなりません。これはいろいろな方法があります。領域確保しているサイズを拡張する、エクステンドを増やす、別にもっと大きなファイルを領域確保してそっちにデータをコピーするetc.。一応自動的に領域確保したサイズを増やすようにしておく仕組みもあるので、これを利用しておけばファイルオーバーフローが起きないかもしれません。
ファイルでもうひとつ書いておくことがあるとしたら、ブロック化レコードについてです。いくつかのレコードをまとめて1つのブロックにすることができます。例えば、1レコード80バイトのレコードを3つまとめて240バイトのブロックにすることができます。この場合、レコード長80バイト、ブロック化係数3、ブロック長240バイトとなります。
A−VXのファイル管理上の仕様の関係でファイルを作成する時に気をつけることがあります。ブロック長を256の倍数か、それよりちょっと少ない値にするとちょっとお得です。例えば、レコード長80バイトのファイルがあったときに、ブロック化係数2にするとブロック長は160バイト、ブロック化係数3にするとブロック長は240バイトになります。160バイトと240バイトのうち、どちらが256の倍数に近いかを考えるとブロック化係数3のブロック長240バイトの方が近い値になります。従ってブロック化係数3を選択するべきです。 どうして256の倍数にすると良いのかは、少し難しい話になるので省略しますが、常にA−VXのブロックはセクタの先頭から開始しているということと関係します。
- 9.ライブラリファイル
たぶん、アプリケーション(Windowsでxxx.exeというような物)はどこにあるの?という疑問を持っているのではないでしょうか。A−VXの世界では、Windowsでxxx.exeというような実行する形式の物を「ロードモジュール(LM)」と呼び、ロードモジュールライブラリファイルの中に入れています。
同じようにCOBOLなどのソース(ソースユニット(SU))はソースユニットライブラリファイル(SULファイル)、コンパイルユニットはコンパイルユニットライブラリファイル(CULファイル)、ジョブストリーム(JS)はジョブストリームライブラリファイル(JSLファイル)、パラメータメンバ(PM)はパラメータメンバライブラリファイル(PMLファイル)に入っています。
Windowsは、ソース(.cppとか.bas、.frmなど)や実行形式のプログラム(.exeや.comなど)がそれぞれ独立した1つのファイルとなっていますが、A−VXのファイルの場合、ソースはソースユニットライブラリファイルの中のメンバの1つ、ロードモジュールはロードモジュールライブラリファイルの中のメンバの1つになっています。ロードモジュール、ソースユニットなどのメンバは最大6文字までの名前を付けます。
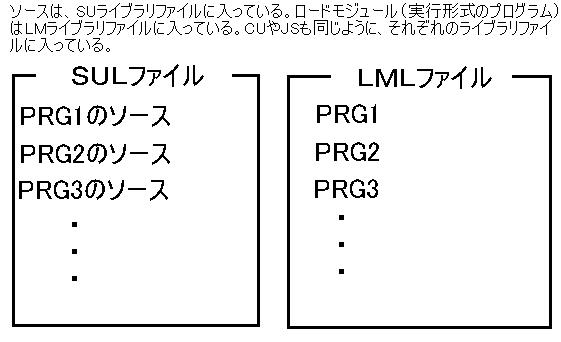
さきに書いたように待機区分編成ファイルや待機結合編成ファイルがライブラリとなります。
ライブラリファイルは用途によってさらにいろいろな種類に分けられています。
主要なものを表にしました。表に示したものの他にもいくつか種類があります。
QP・・・待機区分編成ファイル QL・・・待機結合編成ファイルライブラリファイルの主な種類(説明書などに使われている略称、ファイル編成) 名称 略称 編成 概 要 ロードモジュールライブラリ LML QP ロードモジュールを入れるライブラリファイル ソースユニットライブラリ SUL QL ソースユニットを入れるライブラリファイル コンパイルユニットライブラリ CUL QL コンパイルユニットを入れるライブラリファイル ジョブストリームライブラリ JSL QL ジョブストリームを入れるライブラリファイル フォームオブジェクト FO QP フォームを入れるライブラリファイル 音声単語ファイル VOW QP 音声認識で使われるファイル 音声パターンファイル VOP QP 音声認識で使われるファイル パラメータライブラリ PML QL パラメータメンバを入れるライブラリファイル ドキュメントファイル DOC QL PRISMのドキュメントを入れるライブラリファイル 表データ定義ファイル DBDIR QL 表データ定義を入れるライブラリファイル ユーザスプールファイル SPOOL QL ユーザ用のスプールファイル
ちなみに富士通のオフコンには直接データ編成ファイルなるものがありますが、これと同等のファイル形式はA−VXにありません。同じことを実現しようとしたら、たぶんA−VX/RDBを使用することになるでしょう。
- 10.ファイルの機能
-
ほとんど使われないと思いますが、世代ファイルなどというものもあります。
A−VXはファイル自体にいろいろな機能を付けることができます。
- ファイルエラー時の自動リカバリ方法の指定
- ファイルの満了日
- 書き込み時、書き込み検査付き
- キーブロックの使用効率
- ファイルオーバーフロー時の自動領域拡張
- オーバーフローチェック(オーバーフロー前に警告メッセージで通知する)
- 電源瞬断時の強制クローズ
一般的にはファイルの領域確保時に設定することができますが、幾つかの機能は後で変更することもできます。
これらの機能のうちいくつかは、簡易操作ユーティリティ(#ABC)やSMARTのファイルアロケートで設定できません。このようなものは新システム体系ユーティリティの「システム運用管理支援」→「ユーザファイルの登録」で行う必要があります。
- 11.ファイルのセキュリティ
WindowsやUNIXにファイルのセキュリティがあるのと同じように、A−VXのファイルにもセキュリティという考え方があります。このセキュリティの仕組みは非常に簡単なのですが、WindowsやUNIXとは異なっているので、そちらのOSから入った人は違いにとまどうことになると思います。
- 12.ボリュームやファイルを管理しているもの
A−VXは、システム全体のファイルやハードディスク内のファイルを管理するために、いくつかのシステムファイルを用意しています。全く意識しなくて良いもの、サーバ管理者レベルで使用するものなど異なります。
ファイルの管理の仕組みを知らなくても使えますが、万が一トラブったときのために理解しておいたほうが良いので、少しだけ説明しておきます。
ファイル名 簡単な説明 SYS@FDF ファイルディレクトリファイル。磁気ディスクのボリューム毎(MSDxxx)に各1個ある。ボリューム内にあるファイルのいろいろな情報が保存されている。データ管理説明書にいろいろ説明が書いてあるが、A−VXのシステムが使用するもので、一般ユーザは全く意識する必要は無い。このファイルが壊れたりするとデータファイルが読めなくなったりするので、非常にまずい。当然ユーザが勝手にこのファイルを削除したり作ったり中身を書き換えたりファイルサイズを変更したりといったことはできない。 SYS@FSDF フリースペースディレクトリファイル。磁気ディスクのボリューム毎(MSDxxx)に各1個ある。ボリューム内にある未使用の領域の情報が保存されている。データ管理説明書にいろいろ説明が書いてあるが、A−VXのシステムが使用するもので、一般ユーザは全く意識する必要は無い。当然ユーザが勝手にこのファイルを削除したり作ったり中身を書き換えたりファイルサイズを変更したりといったことはできない。 SYS@CAT ボリュームカタログファイル。システムに1個、SRVと呼ばれるボリュームに作られる。最初にA−VXをインストールするときに作られ、その後は(例えオーバーフローしたとしても)ファイルサイズは変更できないので、最初に大きすぎず小さすぎずちょうどいいサイズで作らなければならない。物理ファイル情報、リモートファイル情報、RDBファイルや仮想表の情報が格納されていいる。 SYS@DDF データディクショナリファイル。データベースも使わないし、このファイルが提供する数々の便利機能も使わない、というようなシステムならば必要ない。それ以外ならばシステムに1個作ることになる。データベースの実表や仮想表(ビュー)の情報を登録したり、一般ファイルのフィールド情報を登録したりする。SMARTやその他いろいろユーティリティで情報を登録したり使用したりとよく使われる。このファイルのサイズによって、そのシステムで使用可能な仮想表(ビュー)の数が決まる。このため無計画に仮想表を作ったりしていると、オーバーフローしたりすることがある。こうなるとそれ以上仮想表は作れなくなり、ファイルサイズを拡張しなければならないので面倒。 SYS@DBDIR データベースの実ファイルの情報を管理しているファイル。説明書ではSYS@DDFとセットで出てくることが多い。SYS@@DDFと同様データベースを使うならば、システムに1個必要となり、このファイルのサイズ次第でデータベースの規模が決まるので、設計が悪いとオーバーフローしたりするので面倒。 - 13.もっと詳しく知りたい
そういう時は
・A−VXの「データ管理説明書」
・古い「コンピュータのファイルについての解説本」
システムファイルが壊れたり、オーバフローしたりした時は
・A−VXの「システム導入・変更の手引き」
ファイルは重要なので、次以降でもう少し詳しく書きます。



ちなみにブロック化係数1にして1ブロック80バイトにしたら、176バイト分未使用(無駄)になります。ブロック化係数4にして1ブロック320にすると、256の2倍512バイトが単位になり、512−320= 192で192バイトが未使用(無駄)になります。
あまりブロック化係数を大きな値にしても仕方が無いので、1レコード80バイトならブロック化係数3あたりが無難なところ。
もしレコード長90バイトならブロック化係数2と3のどちらを選ぶべきか。ブロック化係数2だとブロック長は180バイト、ブロック化係数3だとブロック長は270バイトです。これならブロック長180バイトを選択した方が良いでしょう。(256−180=76、512−270=242)実際はそれよりもブロック化係数5の450バイト(512−450=62)やブロック化係数8の720バイト(768−720=48)の方が良さそうですが・・