順編成ファイルについてもう少し詳しく
- 1.どんなファイルか
-
順編成ファイルは、先頭あるいは前回最後に書き込んだ続きから順番に書き込み、先頭から順番に読み込みできるファイルです。
<読み込み>
必ず先頭から順番にデータを読み込むことになり、途中からデータを読み込むことができません。もし途中のレコード(データ)が必要ならば、先頭から目的のデータまでの途中のデータを読み捨てていきます。
<書き込み>
書き込みは先頭から順番に行うほかに、前回書き込んだ次から順番に書き込むことができます。磁気ディスク(ハードディスク)とフロッピーディスク上の順編成ファイルの場合には、読み込んだデータを変更して、そのデータを元の場所に書き戻すことと、読み込んだデータを削除することができます。あるデータをファイルの途中に挿入することはできません。
- 2.4つの処理モード
-
A−VXの順編成ファイルには4種類の処理モードがあり、ファイルのオープン時にそのうちのどの処理モードでファイルにアクセスするかを決めます。一度モードを決めるとファイルをクローズするまで変わりません。もしモードを変えたいならば、一旦クローズして目的のモードで再度オープンしなければなりません。
<入力処理モード>
ひたすらファイル先頭から順番にレコードを読み込むモード。ファイルに対する書き込みは一切できない。
<出力処理モード>
入力処理モードとは逆に、ファイル先頭からレコードを順番に書き込むモード。前に書いたレコード(データ)は上書きされて残らない。ファイルからの読み込みは一切できない。
<更新処理モード>
先頭から順番に読み込み、そのレコードのデータを変更して同じ場所に書き込むことや削除することができる。
磁気ディスク(ハードディスク)とフロッピーディスク上の順編成ファイルの場合だけ選べるモード。
<追加処理モード>
現在のファイルの最後のレコードの次のレコードから書き込んでいくモード。出力処理モードとは異なり、前回書き込んだデータは残したい場合に使います。
- 3.出力処理モードと追加処理モードの違い
-
ファイルには、EOD(レコード終了アドレス)というものがあり、これで最後にどこまで書き込んだかを覚えています。ファイルの先頭からEODの指しているレコードの1つ前のレコードまでが、使用している(データの入っている)レコードとなります。
A−VXではSYS@FDFというファイルでそのボリュームに存在する全てのファイルの情報を管理しており、EODもSYS@FDF中に格納されています。
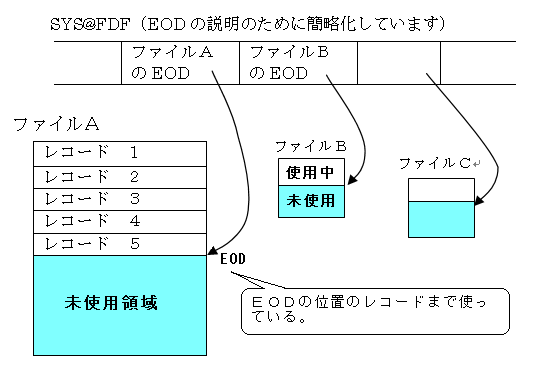
追加処理モードの場合は、EODの指しているレコードから書き込みを行います。一方、出力処理モードの時は、EODを一旦ファイルの先頭のレコードに戻してから書き込みを行います。
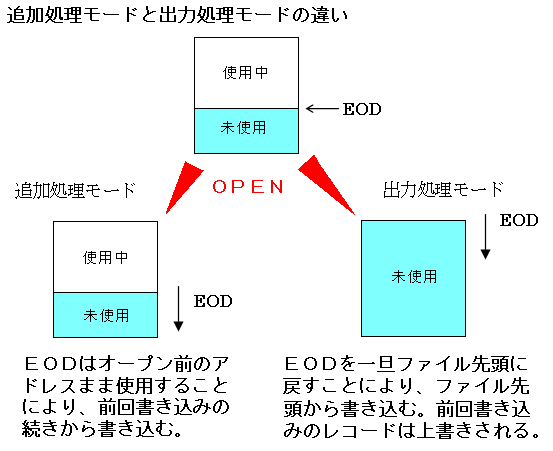
出力処理モードでは、EODをファイル先頭に戻すだけで、ファイル中のレコード内のデータは何も書き換えないというところに注目してください。
なぜ、EODの説明をしているかですが、EODの仕組みがわかるとファイルの復旧ができるかもしれないからです。
例えば、あるファイルに100件のレコード(データ)があるとします。そしてそのファイルをうっかり出力処理モードでオープンしてしまい、2レコード分上書きをしてしまったとします。そうするとファイル上は2レコード書き込み、EODが3レコード目を指している状態になります。出力処理モードではEODの移動しかしないので、98件分のデータは上書きされていません。つまりEODを98件分後ろにずらせば、98件分のデータが復旧できるかもしれないということになります。
EODの移動方法は初級の域を越えているので、ここでは説明しません。EODをおかしくしてしまうと、逆にデータ消失してしまうこともあるので、気をつけてください。
- 4.削除レコード
-
更新処理モードで順編成ファイルをオープンすると、任意のレコードを削除することができます。
システム内部では、レコードの先頭1バイトに16進コードで”FF”という削除コードを書き込むことによって、削除されたレコードにしています。
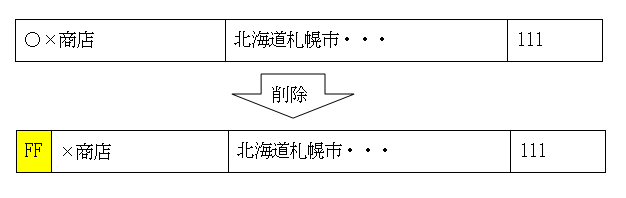
先頭1バイトが”FF”という特殊なコードになっているとシステムが削除レコードと判断されるため、仮にレコードを削除したとしても、システムは1バイト目だけしか書き換えず、2バイト目以降のデータはハードディスク上に残っています。ということは、1バイト目を”FF”以外に書き換えれば、削除レコードではなくなるということです。A−VX付属のユーティリティを使えば、1バイト目を書き換えることができます。もしうっかり削除してしまったとしても、元のデータの1バイト目がわかっていれば、ユーティリティを使って1バイト目を元に戻すことにより、データを復帰させることができます。
また、そもそも1バイト目を使用しないようにすれば、(例えば先頭を1バイトのキャラクタフィールドとしておいて、そこは何も使わない)うっかり削除してしまっても、削除コード”FF”を”40”なり適当な値に書き換えれば元に戻り、元データが何であったかを思い出す必要はなくなります。
- 5.ファイルのオーバーフロー
-
削除レコードはそのままでは再利用されません。
このためどんどんレコードを削除していくと、削除レコードが増えていきます。そして削除レコードが増えると、ほんの少ししかレコード(データ)が入っていないのにオーバーフローになってしまうことがあります。
ファイルがオーバーフローになる原因は次の2つです。
・本当にファイルが満杯になっている。(例えば100レコードの大きさのファイルがあったとして、100レコード分のデータが入ってしまっている。)
・削除レコードがたくさんある。(例えば100レコードの大きさのファイルがあったとして、80レコードが削除レコードで、20レコードが使用されている。)
前者の場合、エクステントの拡張や追加、それができなければもっと大きなファイルを作り直すなどで解決させます。
後者の場合は、削除レコードを整理して再利用可能な状態にします。
削除レコードを再利用可能にするには、ファイルの再編成を行います。
ファイルの再編成の方法は、一般的にユーティリティなどを使って、削除コードを持たないレコードのみを抽出して別ファイルに出力するなどの方法が取られます。 削除レコードをなくすことによるもうひとつの効果として、無駄なファイル読み込みがなくなるため、順編成ファイルの読み込みが速くなったりすることもあります。
- 6.チューニング
-
どのくらい効果があるかは、そのシステムの状態によりますが、順編成ファイルのアクセスを高速化できるかもしれない方法がいくつかあります。
初級の域を越えているので、簡単に紹介するだけにとどめます。
- マルチエクステントファイルの場合、シングルエクステントファイルにする。もし1、048,575セクタ以内でマルチエクステントファイルならば、シングルエクステントファイルに作り変えれば速くなるかもしれません。
- 削除レコードの削減。
- データブロック長の変更(これはA−VXのシステムの特性上、ブロック長を 1〜512,769〜1024,1793〜2048,3841〜4096の範囲にすると効率良くファイルアクセスできるため、アクセスを高速化できることがある。)
- アロケータ(#ALLOC)ではなく、簡易操作ユーティリティ(#ABC)か新システム体系ユーティリティのデータ操作支援を使用してファイルを作成する。
- ブロック化係数の値を高くする。(順アクセスの場合は、ブロック化係数の数値が高いほうがI/O効率が良い。)


